Apr 21, 2022 | Read time 2 min
Speechmatics tackles one of machine learning’s biggest challenges, adding formatting of numbers, dates, addresses, and more to its Autonomous Speech Recognition
Speechmatics tackles one of machine learning’s biggest challenges - Entity Formatting, adding formatting of numbers, dates, addresses and more to its Autonomous Speech Recognition using Inverse Text Normalization (ITN).
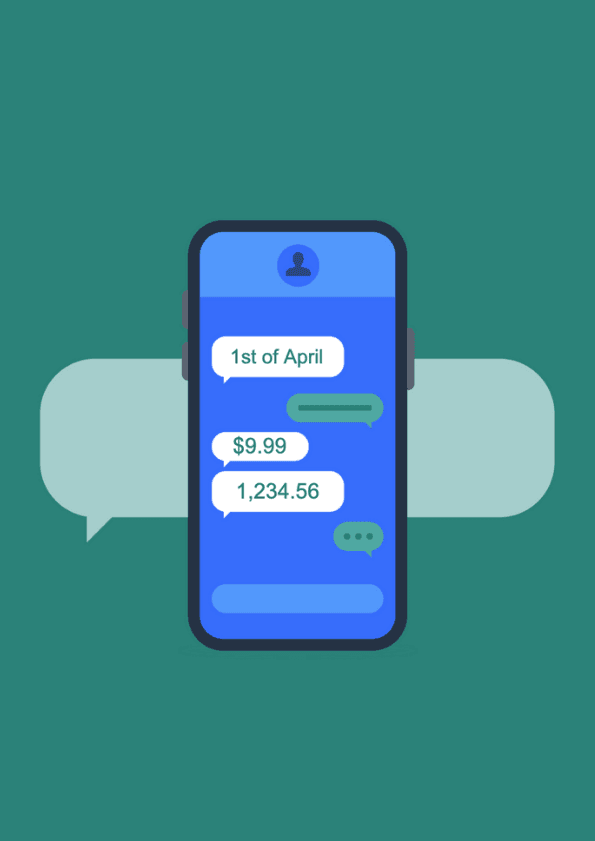

Latest product update sees the addition of consistent Entity Formatting functionality – making transcripts more readable and consistent in 11 languages
Speechmatics, the leading speech recognition technology scaleup, has launched a major step in delivering truly comprehensive speech recognition by adding Entity Formatting functionality to its Autonomous Speech Recognition (ASR) software. Tackling one of machine learning’s biggest challenges, using Inverse Text Normalization (ITN), the software’s ability to consistently and more accurately interpret how entities such as numbers, currencies, percentages, addresses, dates and times should appear in written form makes transcripts more readable and reduces post-processing work.
This update makes using speech recognition technology significantly more valuable to enterprise-level customers, where there is a higher dependency on the consistent and appropriate formatting of numbers in text, such as those in media, financial services and healthcare. Entity Formatting is notoriously challenging in speech recognition because the way that entities are spoken in conversation varies – even between countries that speak the same language – which adds layers of complexity. Telephone numbers are a great example where people might use ‘oh’ instead of ‘zero’ or use double/triple digits such as ‘triple three’.
“Creating a more professional transcript will speed up our customers’ workflows by making large numbers easier to read, requiring less human editing,” says Katy Wigdahl, CEO of Speechmatics. “Context is also critical – there are so many nuances and ambiguities that need to be accounted for in language, such as whether ‘pounds’ is a reference to weight or currency? And whether ‘venti’ is being used as the Italian word for 20 or winds?”
This challenge has overwhelmingly been met: numbers are represented accurately and consistently, dramatically reducing the level of human intervention in the post-editing process. Based on pre-selected standardizations chosen by the customer, numbers can either be represented in written format or spoken in a transcript.
“This new functionality in our breakthrough Autonomous Speech Recognition will have a decisive impact on our customers working in numerically intensive industries,” Wigdahl continues. “Entity Formatting has always been a notoriously challenging task for speech recognition but with this latest update we are delivering best-in-market functionality and bringing significant value to our customers operating in industries where getting numbers right for speech-to-text tasks is mission-critical.”
These new additions follow Speechmatics’ major advances in Autonomous Speech Recognition - its technology is trained on huge amounts of unlabeled data without the need for human intervention, delivering a far more comprehensive understanding of all voices and dramatically reducing AI Bias and errors in speech recognition.